先来看一个案例:小明是一家初创公司电商平台的开发人员,它负责卖家模块的功能开发,其中涉及了店铺、商品的相关业务,设计了如下数据库:

随着公司业务快速发展,数据库中的数据量猛增,访问性能也变慢了,优化迫在眉睫。分析了下问题出现在哪儿呢?关系型数据库本身比较容易成为系统瓶颈、单机存储容量、连接数、处理能力有限。当单表的数据量达到1000W或100G以后,由于查询纬度较多,及时添加从库、优化索引,做很多操作时性能仍下降严重。
文章相关视频讲解:
C/C++ Linux服务器开发高级架构学习视频:c/c++Linux后台服务器开发高级架构师学习视频资料
方案一:
通过提升服务其硬件能力来提高数据处理能力,比如增加存储容量、cpu等,这种方案成本比较高,并且瓶颈在MySql本身,那么提高硬件也是有限的。
方案二:
通过把数据分散到不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。比如:将电商数据库拆分为若干独立的数据库,并且对于大表来说也拆分为若干小表,通过这种数据库拆分的方法来解决数据库的性能问题。
因此,分库分表的目的就是为了解决由于数据量过而导致数据库性能降低的问题,将原来独立的数据库拆分为若干数据库组成,将数据大表拆分成若干数据表,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
分库分表的方式
分库分表的方式在生产中通常包括:垂直分库、垂直分表、水平分库和水平分表四种。
垂直分表
还是以商品信息表为例:用户在浏览商品列表时,只有对商品感兴趣时才会点进去查看商品的详细描述信息。因此,商品信息中商品描述字段访问频率比较低,且该字段存储占用空间较大,访问单个商品IO时间较长;商品信息表中商品名称、商品图片、商品价格等其它字段数据访问频率较高。
由于这两种数据特性不一样,因此考虑将商品信息表拆分为两个小表(t_goods_01,t_goods_02),将访问频率低的商品描述信息单独存放在一张表中(t_goods_01),将访问频率高的商品基本信息单独放在另一张表中(t_goods_02)。
如下所示:

以上这种优化操作,就叫垂直分表。
其定义:将一个表按字段分成多表,每个表存储其中一部分字段。
带来的提升是:
- 为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响。
- 充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率拖累。
为什么大字段IO效率低:
第一由于数据量本身大,需要更长的读取时间;
第二是跨页,页是数据存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越来越多数据库整体性能越好,而大字段占用空间大,单页内存储行数少,因此IO效率低。
第三,数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率高,减少了磁盘IO,从而提升了数据库性能。
一般来说,某业务实体中的各个数据项的访问频率是不一样的,部分数据项可能是占用存储空间比较大的。例如商品描述。所以,当表数据量大时,可以将表按字段切开,将热门字段、冷门字段分别放一个表。
文章福利 Linux后端开发网络底层原理知识学习提升 点击 学习资料 获取,完善技术栈,内容知识点包括Linux,Nginx,ZeroMQ,MySQL,Redis,线程池,MongoDB,ZK,Linux内核,CDN,P2P,epoll,Docker,TCP/IP,协程,DPDK等等。
垂直分库
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器,库内垂直分表直接就了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO和磁盘。
所以,经过思考,把原有的卖家表,分为了商品库和店铺库,并把这两个库分散到不同的服务器,如下图:

由于商品信息与商品描述业务耦合度较高,因此一起被存放在商品库;而店铺信息相对独立,因此单独被放到店铺库。
以上这种优化就叫:垂直分库。
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
它的提升是:
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控和扩展等
- 高并发场景下,垂直分库一定程度上提升IO、数据库连接和降低单机硬件资源的瓶颈
最后,垂直分库通过将表按业务分类,然后分布不同的数据库,并且可以将这些数据库部署在不同的服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
水平分库
经过垂直分库后,数据库性能得到了一定程度上的解决,但是随着业务的增长,商品库单库存储数据已经超出预估。粗略估计,目前有8w个店铺,每个店铺平均150个不同规格的商品,再算上增长,商品数量得往1500w+上预估,并且商品库属于访问频率非常高的资源,单台服务器已经无法支撑。
此时此刻该如何优化呢?
再次分库?但是从业务角度来分析,目前情况已经无法再垂直分库了。
尝试水平分库,将店铺ID为单数的和店铺ID为偶数的商品信息分布存在两个表中。
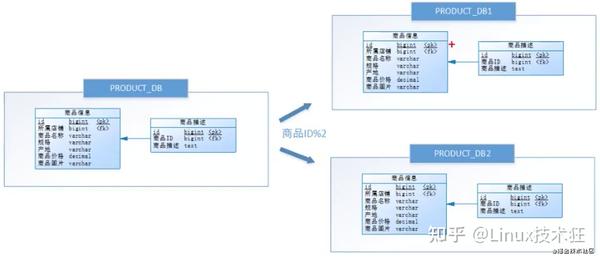
以上的优化就叫:水平分库。
水平分库就是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
对比:垂直分库是不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构。
水平分库的提示是:
- 解决了单库大数据,高并发的性能瓶颈。
- 提高了系统的稳定性和可用性。
当一个应用难以再细粒度的垂直拆分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能的瓶颈。但是由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提示了系统的复杂度。
水平分表
按照水平分库的思路对商品库内的表也进行水平拆分,其目的是为了解决单表数据量大的问题,如下图所示:
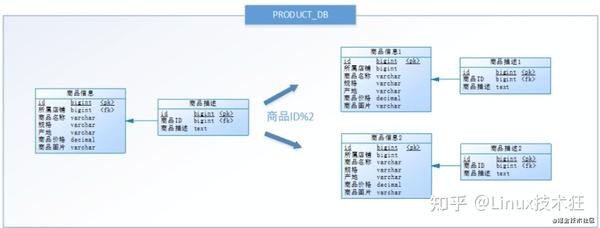
以上操作进行的优化就叫水平分表。
水平分表就是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中(对数据的拆分,不影响表结构)。
它带来的提升是:
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
库内的水平分表,解决了单一表数据量过大的问题;分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
总结
分库分表的方式有四种,它们分别是:垂直分表、垂直分库、水平分库和水平分表。
垂直分表:可以把一个宽表的字段按照访问频率、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提高部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
垂直分库:可以把多个表按照业务的耦合性来进行分类,分别存放在不同的数据库中,这些库可以分布在不同的服务器,从而使访问压力被分摊在多个服务器,大大提高性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
水平分库:可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同的服务器,从而使访问压力被多服务器负载,提升性能。它不仅需要解决跨库带来的问题,还需要解决数据路由的问题。
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表的数据只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
最后,一般来说,在系统设计阶段就应该根据业务耦合程度来确定用哪种分库分表的方式(方案),在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且连续增长,再考虑水平分库水平分表的方案。